San Francisco Trip Part 1
I was visiting San Francisco from June 1 to 7. Here are some pictures I took.

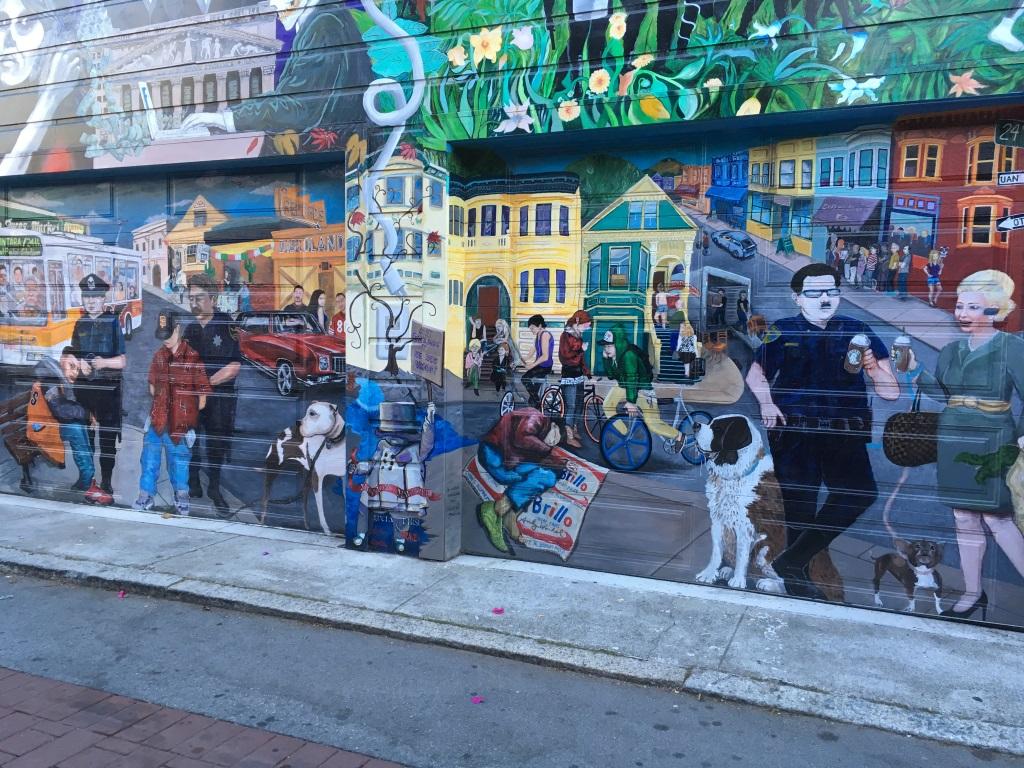
It's nice and warm when the sun is up but it gets really cold as soon as you are in the shade. Ocean wind, I guess. In general, you need to wear a t-shirt and carry a thick sweater to wear in case it gets cold.

I liked seeing many old 80's cars in SF.


The city is also incredibly hilly.

There were many tasty mexican joints as well. A lot more common than the Chinese restaurants in Toronto.

I'll post more later.
Due - my favorite iPhone to-do app
Due is my most favorite todo app. I got it for free from Starbucks but I would totally pay for it. Here's why:
It does not let you forget a to-do item
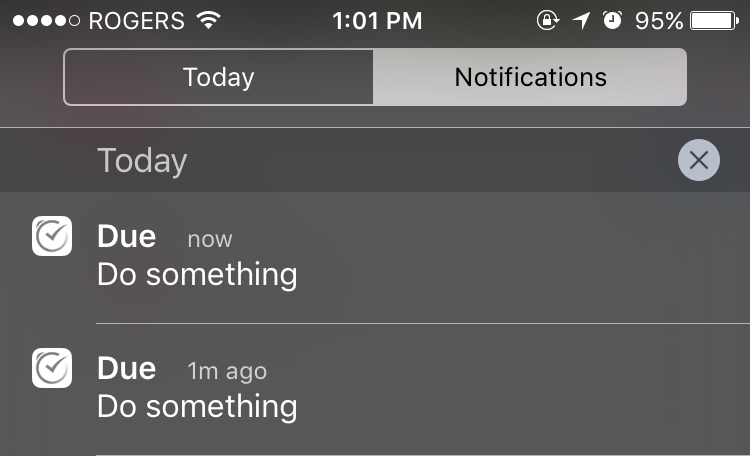

The built-in iOS reminder app reminds you about a to-do item once, but never again. I often forget about a to-do because I don't check the notification area that often. Due will just set off a new notification every 5 minutes, until you either mark it done, or snooze it. You just can't ignore it even when the phone is in your pocket.
There were many times where this "nagging" behavior really forced me to work on important things instead of forgetting them.
Marking it done, or snoozing it is also easy but that's not too different from the built-in app.
Super easy due date/time entry
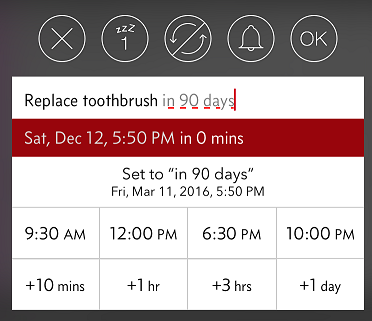
The entry UI is optimized for entering due dates quickly. You can tap to pick a pre-set, but customizable time of day, or add a time interval. You can even type the relative dates as you would talk to Siri.
On the other hand, the built-in reminder app has no way to set a relative (e.g., "in 50 days" instead of "Jan 25, 2015") due date in the UI. You must talk to Siri to do it which a no-go in a meeting.
Auto-import from the built-in app
The app is capable of importing the built-in app reminders so you can easily move from the built-in app to Due. There is also automatic import-and-delete feature so you can keep using Siri for setting reminders.
DPI Scaling on Linux Mint
I have a Surface Pro 2 which has a relatively dense, 10-inch 1080p screen. It hurts my eyes to look at individual UI elements and text without dpi scaling. On Windows, everything is scaled up by 150% by default.
I wanted to use Linux Mint on VirtualBox for development but I couldn't find any articles on the internet on how to get the elements to scale up properly. After some trial-and-error, this is how I achieved 150% dpi scaling that is good enough.
- Go to Preference -> General, then select User interface scaling to be Double. This doubles everything in size. This works for other high density displays like MacBook Pro retina but many things looked too big for the screen of Surface Pro 2.
- Go to Preference -> Fonts, then set text scaling factor to 0.7. This leaves UI elements to be double the size but makes text smaller. Since the text size was doubled then multiplied by 0.7, it ends up being 140% of the original size, which is close enough to the desired level of 150%.
- Log out and back in to finish applying the change.
Offline App Usability Checklist
I started paying attention to offline usability because I was fed up with apps that have really bad offline usability issues.
Living in Toronto, whenever I wanted to use my tablet/cellphone to read something, I am often at a location with no connectivity. For example, I commute daily on TTC Subway and there is no connectivity underground. All food courts I go for lunch have no cell service, either. I get to experience all kinds of good and bad offline support in apps as a result.
When I say 'offline usability', it does not have to be about an app that supports offline mode. Apps with intrinsic online requirements can also have bad offline usability issues (look at the section "Bad Refresh Behaviour"). I would be happy if people read this post and think a bit more about this problem.
Determine the Requirement
You need to determine what needs to work offline versus what does not. There is no point supporting offline mode for something that intrinsically requires connectivity. The requirement highly depends on the kind of application you are building. Here are a few examples:
Email App
Email apps are perhaps the oldest and most mature of all offline capable apps. It has been there since the dial-up days, when always-on connectivity wasn't a common thing.
What data is available offline
Recent emails in Inbox and other specified folders.
What can User do when offline
- User can view offline emails, and attachments depending on the settings.
- User can send an email. The email will be saved in Outbox, and the email will be sent when it is online.
- User can view/delete items in synchronized folders. User can edit items in Drafts and Outbox folder. The action will be propagated to server when it's online.
What settings can User change
- How much to synchronize: 3 days, 5 days, 2 weeks, a month, and all
- How often to synchronize: push, every 5 min, ..., once a day, and never
- What folders to synchronize: Inbox, Outbox, Sent, and other folders
News Reader
What data is available offline
Recent news (e.g., news in the last 24 hours) which is synchronized at some interval.
What can User do when offline
- User can read recent news. Users can look at images attached to news articles.
- User can share the link to social networks, which will be sent when online.
What settings can User change
How often to synchronize: every hour, 3 hours, 6 hours, every day, or never.
What not to do
Here is a list of common offline usability issues. This list is not inclusive.
Incomplete Data
The data available offline must be as a whole and useful form regardless of its internal data structure.
For example, consider a Contact app that only caches list of contact names and not their phone numbers because they are in different database table (or whatever reasons). Not only the contact names are useless to the user, it is frustrating to the user because the app gave a false impression that contacts are available offline. Most importantly, the app probably ruined the user's business for the day.
In this case, it would have been better to cache all of user's contacts and its related information. It is very unlikely that the data won't fit on a modern smartphone. In the unlikely case of too many contacts, we could consider a concept of 'favourites' to synchronize.
Unpredictable Caching
Algorithms like MRU (Most Recently Used) may work for many things but it is largely inappropriate for caching offline user data (unless your user research tells you so). People just don't remember a list of things recently accessed. There are simply too many factors in play to guess what the user needs offline.It is best to have caching rules that are reliable and that humans can easily understand (e.g., none, last n days, all). Obviously, the content should be complete (see the section "Incomplete Data" above).
Bad Refresh Behaviour
This one applies to always-online application as well. Refresh should not invalidate the cache until a successful response has come back.Here is an example of a bad refresh behaviour on Facebook for Android: One morning, I opened up a friend's long status that I wanted to read but I had to leave for work. So I just turned off the screen of my tablet and got on the subway. The moment I turn on the screen, Facebook's refresh on unlock logic kicks in, and blew up the status I wanted to read.
Another bad example is the Korean news portal Naver (news.naver.com). It does a periodic page refresh through location.reload(). If you lose internet connection for 30 minutes, you will find that all Naver news tabs turn into error pages.
Defying Users' Expectation on Online Requirement
Apps should respect User expectations and mental model on whether particular function should be available offline.For example, Users will not accept an email app that requires connectivity for writing a new email. Users of an email app expects the app to save the new email and send it whenever the connectivity is restored.
Shazam is a good example of an app that respects this principle. Shazam listens to a song and finds out what the song is for the user. When there is no connectivity, Shazam listens to a song and saves the recorded sound locally. When the connectivity is restored, Shazam sends and tags the saved sound.
Data Loss from Conflict Handling
Losing or overwriting data without user's consent is probably one of the worst things you can do in information systems.Suppose two users edited a contact, offline. When they come back online, the second save will cause a conflict. It is best if there is a contact merge tool. If there is not one, or if it is too hard to write one, the server could save the second saved contact as a new contact and let the user merge it manually. Just never overwrite the first edit, or lose the second edit.
Conclusion
Designing usable apps for offline use is not easy. You have to decide what needs to be available offline, and how & when to synchronize them. Offline requirements often have huge architectural implications, as well. Therefore, it is important to keep these items in mind at all stages of software development, from design to implementation and maintenance.
Debugging ARM without a Debugger 3: Printing Stack Trace
This is the last post in the series Debugging ARM without a Debugger.
This is an excerpt from my debugging techniques document for Real-time Programming. These techniques are written in the context of writing a QNX-like real-time microkernel and a model train controller on an ARMv4 (ARM920T, Technologic TS-7200). The source code is located here. Mby teammate (Pavel Bakhilau) and I are the authors of the code.
A stack trace is the ultimate tool that can help you tell exactly where a problem is occurring when used in conjunction with asserts (e.g. in my code, an assert failure triggers the stack trace dump. I also wired the ESC key to an assert failure).
It is particularly useful when you have a complex applications with deep call stacks. For example, if an assert has failed in a utility function such as stack_push in a complex application, it is practically impossible to figure out what happened where without putting print statements everywhere.
With a stack trace, we can re-construct the run-time call hierarchy and find out what is happening. At the end of this article, I will present an example of sophisticated stack trace output that can help us diagnose complex concurrency issues.
Stack Frame Structure
We can deduce the exact stack frame structure from the assembly code generated by the compiler (GCC-arm in my case). Here is an example of a typical function header:
func:
mov ip, sp
stmfd sp!, {(other optional registers), sl, fp, ip, lr, pc}
sub fp, ip, #4
; function body continues...
The compiler will save the registers pc, lr, ip, fp, sl into the stack in that order. Additionally, the compiler may save any other scratch register used in the function. Important registers for printing a stack trace are pc, lr and fp.
Note that if any compiler optimization is turned on (e.g. -O flag), you need to pass the extra argument -fno-omit-frame-pointer. Otherwise, GCC will optimize out the code that saves the frame pointer.
pc (program counter)
Reading the saved pc gives us the address of the entry point of the function plus 16 bytes. This is because pc is always 2 instructions ahead in ARM when we save it.
lr (link register)
The lr register is the address to return when the current function returns. An instruction before lr would give us the exact code address of the caller of the current function.
fp (frame pointer)
This is the frame pointer of the previous function. We will need to read this in order to “crawl up” the call graph.
Stack Trace Crawler
Here is the pseudocode (or the actual code) for printing the stack trace:
// a poorly written macro for reading an int at the specified memory address x.
#define VMEM(x) (*(unsigned int volatile * volatile)(x))
lr = 0; depth = 0;
do {
pc = VMEM(fp) - 16;
// print here: the calling code is at lr, the current function addr is pc
if (lr is invalid) break;
lr = VMEM(fp - 4);
fp = VMEM(fp - 12);
if (fp is not a valid memory or depth too big) break;
depth++;
} while (the current function is not a top-level function && depth is < some threshold);
Here's an example code for reading the frame pointer which is required to start printing the stack trace:
#define STRINGIFY(x) #x
#define TOSTRING(x) STRINGIFY(x)
// reads the register reg to the variable var
#define READ_REGISTER(var,reg) __asm volatile("mov %[result], " TOSTRING(reg) "\n\t" : [result] "=r" (var))
int fp; READ_REGISTER(fp, fp);
The most important thing here is that you want this code not to fail. Here are common things that can happen that you don't want:
- Abort inside another abort (or, an abort inception; install a good abort handler to find out why)
- Invalid pointer dereference (e.g. outside the physical memory, or outside .text region)
- Stack overflow which will lead to another abort (by getting stuck in an infinite loop of crazy corrupt frame pointers)
Finding out the corresponding C code
Use the command objdump -SD executable | less to figure out what the C code is at a given address. Passing the compiler flag -ggdb enables objdump to print the C source code next to the disaseembled code. It may not always work with higher optimization level.
Printing the function name
The debugging process can be much faster if you can see the function names in a stack trace right away when the program crashed, instead of running objdump every time manually.
The proper way to do it is to read the debugging information from the .debug section of the memory. I did not have time to do that, so instead I built my own symbol table array using a shell script hooked up to the makefile.
This symbol table does not need to be sophisticated. A simple array of a function address and its name is good enough. This is because the performance is not a concern when you are printing the stack trace of a crashed system. Another reason is that we want this code to work all the time. It is pretty hard to mess up a linear search.
The symbol array is built off the exported symbols. The method I have used is simple. After compiling all the source code into assembly files, I run a shell script to search for the string “.global” in all the assembly files to generate the exported symbol table. Then I compile the generated code of exported symbols as well, and then link it all together at the end. The following is a sample code how to do it:
funcmap.h (funcmap provides the interface to find function names given an address)
typedef struct _tag_funcinfo {
unsigned int fn;
char *name;
} funcinfo;
/* call this before calling find_function_name */
void __init_funclist();
funcinfo *__getfunclist();
/* call this function to find the name of the function */
static inline char* find_function_name(uint pc) {
funcinfo* fl = __getfunclist();
int i = 0;
while (fl[i].fn != 0) {
if (fl[i].fn == pc) return fl[i].name;
i++;
}
return "[unknown function]";
}
funcmap.c (generated by a shell script)
#include <./task.h> // include ALL the header files
static funcinfo __funclist[1]; // the length of this array is also generated
void __init_funclist() {
int i = 0;
__funclist[i].fn=(unsigned int)some_func;
__funclist[i++].name="some_func";
// .. more
__funclist[i].fn=0; // null terminated
}
funcinfo* __getfunclist() { return __funclist; }
Lastly, this is how I read all the function names from assembly files in the shell script (the actual script):
FUNCTION_COUNT=`find . -name '*.S' -o -name '*.s' | xargs grep .global | awk '{print $3}' | grep -v '^$' | grep -v '^__' | sort | uniq | wc -l`
FUNCTIONS=`find . -name '*.S' -o -name '*.s' | xargs grep .global | awk '{print $3}' | egrep -v '(^$|^__|PLT|GOT|,)' | sort | uniq`
Putting it all together (Example)
Combining the stack trace with task information can be even more powerful than what basic C debuggers offer.
The following is an example of a stack trace output for multiple tasks. It prints two lines per task.
Task 0 {noname} (p:31, pc:0x2180b8, sp0x1edfe34, lr:0x2506d8, WAITING4SEND):
nameserver @ 0x2505e8+0,
Task 1 {noname} (p:0, pc:0x24c55c, sp0x1eafff0, lr:0x21809c, READY):
kernel_idleserver @ 0x24c550+0,
Task 3 TIMESERVER (p:31, pc:0x2180b8, sp0x1e4ff80, lr:0x21d1cc, WAITING4SEND):
timeserver @ 0x21d074+0,
Task 4 {noname} (p:31, pc:0x2180d0, sp0x1e1ffe0, lr:0x21f818, WAITING4EVENT):
eventnotifier @ 0x21f7c4+0,
Task 5 IOSERVER_COM1 (p:31, pc:0x2180b8, sp0x1deff04, lr:0x21eab8, WAITING4SEND):
ioserver @ 0x21e82c+0,
Task 6 {noname} (p:30, pc:0x2180d0, sp0x1dbffe0, lr:0x21f818, WAITING4EVENT):
eventnotifier @ 0x21f7c4+0,
Task 7 IOSERVER_COM2 (p:31, pc:0x2180e0, sp0x1d8fe6c, lr:0x21e104, RUNNING):
[unknown function] @ 0x21df94+0, ioserver @ 0x21e82c+253,
Task 8 {noname} (p:30, pc:0x2180b0, sp0x1d5ffe0, lr:0x21f830, WAITING4REPLY, last_receiver: 7):
eventnotifier @ 0x21f7c4+0,
Task 9 {noname} (p:2, pc:0x2180b0, sp0x1d2f878, lr:0x22006c, WAITING4RECEIVE):
uiserver_move @ 0x220018+0, timedisplay_update @ 0x23bed4+49, dumbbus_dispatch @ 0x21a5a8+15, a0 @ 0x234c88+646,
Task status code:
WAITING4SENDmeans the task is waiting for another task to send a message.WAITING4RECEIVEmeans the task has sent a message but the receiver has not received the message yet.WAITING4REPLYmeans the task has sent a message and someone received it but has not replied yet.last_receivertells us the last task that received the message from this task.WAITING4EVENTmeans the task is waiting for a kernel event (e.g. IO).READYmeans the task is ready to run next as soon as this task becomes the top priority task.RUNNINGmeans the task is currently running.
The first line displays the task number, name, priority, registers, task status and the task synchronization information. The second line displays the stack trace with the offsets from the address of the function.
Why is this powerful? We can use this to solve really complex synchronization issues with wait chains & priorities that is otherwise nearly impossible to without this information. At the end, we had more than 40 tasks interacting with each other and my life would have been much harder without this information.
Limitations
The major limitation of this method is that it can't print the names of static functions. This is because the symbols for static functions are not exported globally. This is not a huge problem because you can still see the names from the output of objdump.