The Ruby Tutorial that I wish I had
I've moved to a new team recently. Some of the infrastructure definitions were written in Ruby. Ruby isn't a language I'm familiar with but I know a handful of programming languages, including Python, so I thought it would be trivial to pick up. I was very wrong.
Whenever I read Ruby, I felt lost. I genuinely had no idea how to interpret most of the program I was looking at. The code snippets just looked magical to me. I found it even more confusing than C++, which I had been programming for the last 2 years and has its own reputation for complexity.
I spent several frustrating nights studying to get to a point where I could understand relatively simple Ruby code. I quickly went through the official docs, starting with To Ruby from Python and combed through the FAQ. Still I felt I didn't really understand the language. I couldn't find answers to basic things like when I can/cannot omit brackets when calling a method.
I don't want other experienced programmers to go through the frustration I had so I want to share what I've learned to help others get started with Ruby. Here's a tutorial that I would have found useful 2 weeks ago.
Since it's a long collection, here's the table of contents for your convenience:
- Ruby is a lot more Object-Oriented
- Fun with Modules
- Diversity of Method definition/call Syntax
- Syntactic Sugar for Setters
- Blocks
- Procs
- yield
- procs
- Percent Strings
- 3 Ways to Write a Hash
- instance_eval for that Magic DSL look
- Conclusion
Ruby is a lot more object-oriented
Ruby is more object-oriented than many other mainstream programming languages. For example, in Ruby, it is a lot more idiomatic to use methods attached to basic classes like Integer, rather than to use a free function. Take a look at how to count from 0 to 4.
5.times {|x| puts x}
Compare this to what I'd do in Python:
for x in range(5): print(x)
As far as I can tell, there is no obvious distinction between primitives and objects. Java has a fairly strict division across the two types, like how an int doesn't have any methods. In Python, built-in types like int are a bit more object-like.
1.__add__(2) # this is SyntaxError
(1).__add__(2) # This is OK - 3
The Python built-ins are still special in a sense that they cannot be overridden.
>>> int.__add__ = lambda x, y: y
Traceback (most recent call last):
File "", line 1, in
TypeError: can't set attributes of built-in/extension type 'int'
In Ruby, extending/overriding core classes is possible. The following code adds a method named add1 to Integer.
# in Ruby, this adds the following to the existing Integer definition.
class Integer
def add1
self + 1
end
end
puts 2.add1 # prints 3
I'll leave it up to you to decide if it's a good thing or not 😉
In addition, there is no free function. That's just like Java, but you can define methods without a function. So where do they go? The answer is that it's attached to the class Object. You can inspect this yourself by running the following script:
def test; 42 end
puts method(:test).owner
# output: Object
Since every object in Ruby derives from Object, does this mean these functions are effectively global functions that are in every single class? The answer is yes. Check out the following example:
class B
def answer
puts "fun_in_main owned by #{method(:fun_in_main).owner}"
fun_in_main
end
end
def fun_in_main; 42 end
puts B.new.answer
# output
fun_in_main owned by Object
42
Fun with Modules
Ruby modules have two purposes. First, they can organize classes and methods into a namespace. In that respect, it's a lot like a Python package. Interestingly, Ruby modules are also used as a template for mixing in methods into a class. What I found confusing about this was that a module itself is the target of mixin, rather than a class in the module. To me it makes more senes to have a class mix into another class, rather than have a module mix into a class. Then I realized that the syntax for creating "free functions" in a module looked like a static class method. So I started wondering, are modules and classes the same? To investigate this, I ran the following experiment:
module Quacks
# effectively a free function under Quacks namespace
def self.static_quack
puts "static_quack"
end
# for use as a mixin
def quack
puts "quack"
end
end
class Duck
include Quacks # now I can use all methods from Quacks
end
Quacks.static_quack # => prints static_quack
Duck.new.quack # => prints quack
In this code snippet, static_quack is a static method to the module, so the module is being used to emulate a free function. On the other hand, quack is meant to be mixed into the class Duck when include Quacks run.
irb(main):009:0> Quacks.new
Traceback (most recent call last):
2: from /usr/bin/irb:11:in `'
1: from (irb):82
NoMethodError (undefined method `new' for Quacks:Module)
It's not quite a class since it doesn't have the new method. But it does kind of look like a class because it has all the class-like methods:
irb(main):010:0> Quacks.instance_methods
=> [:quack]
irb(main):011:0> Quacks.methods false
=> [:static_quack]
Answer to my question: they are similar but not the same thing.
Diversity of Method definition/call Syntax
In Ruby, there is no attribute/method distinction. Everything is a method by default, but they do look like attributes. That's good for encapsulation but I found this one of the most confusing part of the Ruby syntax. Consider the following class:
class Sample
def x
3
end
end
The class Sample has a method/attribute named x, so you can access it like the following:
s = Sample.new
puts s.x()
But you can also call x like this:
puts s.x
For any zero-argument method, you may omit the normal function call braces.
The next question I had was, how would I get the reference to the method itself, if the method name invokes the method right away? The answer is to use the method method and pass in the name of the method as a symbol.
m = s.method(:x)
m.call # calls s.x
Then this method call be called using call() like in the example. Note this method is bound to the object by default, which can be retrieved by calling s.receiver.
This terse method call syntax also extends to single argument calls. In the following example, f is a method that takes a single argument and adds 1 to it.
class AddOne
def f x
x + 1
end
end
But it's also valid put the brackets around formal arguments like this:
def f(x)
...
end
The same applies when calling the method. Both styles are valid:
a = AddOne.new
a.f 1 # => 2
a.f(2) # => 3
But when the method has two or more arguments, you must use brackets around the method call.
def add_two(a, b)
a + b
end
add_two(1, 2) # => 3
add_two 1,2 # => 3
add_two 1 2 # => not OK
I found this kind of inconsistent, considering languages like F# that has a similar function application syntax allows the second form (with currying).
Syntactic Sugar for Setters
class Holder
def initialize
@x = 3
end
attr_accessor :x
end
h = Holder.new
h.x= 1 # Ok this makes sense, it's a short-hand for h.x=(1)
What the tutorials didn't tell me is why code like the following works:
h.x = 1 # Why does this work? and what does it even do?
At a glance, it parses in my head like (h.x) EQUALS TWO. It took me a while to find out the answer. It's a syntactic sugar--Ruby will convert that into a method call into x=. In other words, all of the following are the same:
h.x=(1)
h.x= 1
h.x = 1
We can deduce from this syntactic sugar that the "get_x/set_x"-style method naming convention doesn't make too much sense in Ruby. When an attribute-like method name ends with =, we know it's a setter, and otherwise it's a getter.
Blocks
Ruby has blocks, which are kind of like lambdas in Python in that you can pass in a block of code to be executed by the method. Here is an example:
5.times {|x| puts x} # prints 0 1 2 3 4
5.times do |x| puts x end # same as above
Of course, in Ruby, there are two ways to write the same thing, but that's fine, I am used to that by now. What I found complicated was how to actually use them and how they interact with other method parameters. First, all methods in Ruby will take an implicit block, after the last parameter. In the following example, it's okay to call f with a block because every method accepts an implicit block. f just doesn't use it.
def f a
puts "f is called with #{a}"
end
def f_no_argument; end
f(5) {|x| puts "block called" } # this block is unused.
# Output
# f is called with 5
Note that a block is not exactly the same as the last argument to the call. It must be specified outside the brackets for the arguments (if they are around).
f(5) {|x| puts "block called" } # OK
f 5, {|x| puts "block called" } # not OK
# No-argument examples
f_no_argument {|x| puts "block called" } # OK
f_no_argument() {|x| puts "block called" } # OK
Once inside a method, calling the passed-in block requires using the keyword yield, which means a very different thing than in Python.
yield
yield in Ruby executes the block passed in. yield is a bit special compared to regular function calls because Ruby doesn't seem to validate the number of arguments in the block. For example, calling the following method f without any argument will give you ArgumentError:
def f x; puts x end
f 1 # ok
f # ArgumentError (wrong number of arguments (given 0, expected 1))
But calling a block with a wrong number of arguments is fine.
def f
yield
yield 1
yield 1, 2
end
f {|x| puts x} # not a problem
The missing arguments are substituted with nils.
procs
Unlike lambdas, blocks are not really assigned to a variable. In order to actually grab the block and do the normal variable-like things (e.g., storing it, or forwarding it), you can accept it as the last argument prefixed with & to auto-convert it to a proc, which is then bound to a normal variable.
def addOne(x, &p)
# p is a Proc
p(x + 1)
yield x + 1
end
addOne(1) {|x| puts x}
# output:
# 2
# 2
In this example, p refers to the block that prints. Note that yield also continues to work.
Procs can be converted back into a block argument to another function by prefixing & again. In the following example, forward takes a block as a proc, then converts it back to a block, to be passed into Integer#times.
def forward &p
2.times &p
end
forward { |x| puts x }
# output:
# 0
# 1
Percent Strings
Percent Strings are another type of syntactic sugar that makes it easy to write a certain constructs like symbol arrays. But if you have never seen them before, you can't really guess what they mean. Here are some of them:
# %i for symbol arrays (i stands for what?)
%i(a b c) # => [:a, :b, :c]
# %w is like %i except it gives you a string array (w for words?).
%w(a b c) # => ["a", "b", "c"]
# %q for a string (q for quotes?)
%q(a b c) # => "a b c"
# %r for a regex pattern (r for regex?)
%r(a b c) # => /a b c/
# %x is a subshell call (x for.. eXecute?).
%x(echo hi) # => "hi \n"
`echo hi` # just one more way to do it
3 Ways to Write a Hash
Most tutorials cover 2 different ways to write a Hash (i.e., dict in python). The first is the most verbose way, listing each key and value:
x = {"a" => 1, "b" => 2}
The second way is a short hand, if you want the keys to be symbols:
x = {a:1, b: :b}
x = {:a => 1, :b => :b} # equivalent to line above
What tutorials often don't cover is the third shorthand-form, which can be used only as the last argument to a method call.
puts a:1, b:2 # prints {:a=>1, :b=>2}
In this case, a and b are symbols. Again, this only works if the hash is the last argument to a function call.
puts 1, a:1, b:1
Curiously, this does not work for assignment, or an assignment-like method call. Check out the following:
class Test
attr_accessor :member
end
t = Test.new
t.member = a:1 # does not work
t.member= a:1 # does not work
t.member=(a:1) # does not work
instance_eval for that magic DSL look
The last core ingredient for understanding Ruby is instance_eval. instance_eval takes a block and will run the block in the context of that instance. Effectively it just swaps the self of the block. The following demonstrates something that resmbles a typical Ruby DSL. It will let you configure a Hash in a cool-looking way.
class DSLTest
def initialize
@config = Hash.new
end
def configure
yield @config
end
def run &p
instance_eval &p # this means to convert the proc p back into a block
puts "Configuration is #{@config}"
end
end
x = 9
DSLTest.new.run do
configure do |c|
c[:key] = x
end
end
# prints Configuration is {:key=>9}
Conclusion
Matz, the creator of Ruby, wanted a “[…] a scripting language that was more powerful than Perl, and more object-oriented than Python”. And I can certainly agree that Ruby has achieved both. It is more object-oriented than Python. It is also Perl-like- in both good and bad ways. Ruby can be concise and powerful, but I can't help feeling bothered by how there is always more than one way to do something. I don't like it, but I can now read Ruby code without being completely intimidated, at least. I hope this post is helpful to those who struggle to understand Ruby.
Essay on Inheritance - Popular, Attractive, and Not Very Good
Despite being one of the most popular code-reuse pattern, inheritance often leads to messy, less maintainable codebase in the long term. Why is it popular if it's bad? What can you do instead?
Inheritance is still a widely used tool in software design. I think there is something fundamental to inheritance that makes it attractive to software developers. But it’s not often the right tool to use.
Ten years ago, I was doing web development. The web application I was working on used Widget classes which produced HTML and JavaScript markup for the browsers. Unfortunately, we were still dealing with ancient quirky browsers, so we had to emit different markup for different browsers. We decided to use inheritance to solve this problem. We named each class after the browsers they support: IEWidget and FirefoxWidget, each inheriting from Widget.
The subclasses overrode relevant functions to adapt to different browser behaviours. This worked well for a while until a new popular browser called Chrome entered the market. The natural reaction to this was to create a new subclass for Chrome, except this couldn’t be done without duplicating a lot of code from the other classes. Clearly, the class design wasn’t working very well.
Stack could be implemented use an ArrayList as a member, rather than inheriting from it.
It became much worse as we moved into the wild world of mobile browsers where there were more than a handful of browsers with different quirks. It was obvious to me this design didn’t really scale but I didn’t know what to do back then.
Over time as I worked with more code, "composition over inheritance" suddenly clicked. I've read about it before, but it wasn’t obvious to me how to apply it well. I’ve worked at a few more companies since then, but I still see it misused all the time.
Popularity of Inheritance
In 2001, Joshua Bloch wrote in Effective Java why we should favour composition over inheritance. It’s been almost two decades since then. Why do we keep seeing this? I can think of a few reasons for this.
First, there is a whole generation of developers who were taught inheritance as the primary method of OOP design. Many earlier popular libraries have been written using inheritance. The famous unit test framework JUnit introduced the concept of unit test classes where you inherit from the base TestCase class. JUnit moved on to the new annotation-based style but it didn’t stop developers from structuring tests the old way. Newer frameworks like pytest use composition via dependency injection as the primary method for organizing test dependencies. My experience with pytest has been very positive. The framework naturally leads to more modular tests.
Fortunately, this seems to be going away. When I took a software design course in 2011, they didn’t teach composition over inheritance. Now it seems to be part of the curriculum.
Second, inheritance offers the path of the least resistance for implementation reuse. Mainstream languages like Java do not offer a convenient way to do composition, at least compared to inheritance. Inheritance gives you a special syntax to construct your parent class, for example. Compare that to composition where you have to pass the object via a constructor, add a member variable, and then every method call over that object has to be qualified with the name of the object. It feels wrong to have to go through so many steps! Combined with the tendency for Java developers to have verbose variable names, no wonder many people default to inheritance (just imagine having to write abstractCollection.x(), instead of x() for every delegated function x).
Another reason is that it takes a lot of experience and deliberate thinking about software design to understand and experience issues with inheritance. Let’s go back to the WebWidget example I mentioned earlier. The design worked fine for many years until the requirements changed (i.e., numerous new browsers). Once the requirements outgrew the design, the signs of a design breakdown like downcasting appeared in the codebase (i.e., instanceof in Java & dynamic_cast in C++). Unfortunately, by the time this happens, the original designers may not even be around to learn the consequences of their design. Even if they were around, they would have to know about the alternative design choices (like composition) to realize how it could have been done differently. Put it another way, you have to be at the right place at the right time to learn the lesson.
Deadly Attraction of Inheritance
Unlike the long-term downsides, there is an immediate upside to using inheritance. It gives developers nice, warm feelings right away. Seriously, developers have an occupational disease—genericitis—for both reusing code and categorizing objects, sometimes to their demise. Inheritance as a tool does both, so it’s insanely attractive for developers. It’s a dangerous trap, really. It feels good now, but it hurts you later. Many leaders in software design have been warning us about this particular trap through rules like composition over inheritance, the rule of three and YAGNI (you aren’t gonna need it). Unfortunately, they are not as well-known as principles like DRY (don’t repeat yourself). My explanation for this is that principles like the rule of three embody the next level of understanding above principles like DRY. This is something worth exploring more deeply.
Underneath the rule of three is the learning that we are not so good at predicting the future. This is well-known in the project management circles as the cone of uncertainty. Software design at its core is about making bets about the future. We predict what data belongs where, and how objects will interact with each other. When we get the design right, it pays off by making the code easier to modify and extend. On the other hand, when you make a wrong design decision, it bites us back with higher maintenance costs later. The stronger your prediction is, the more expensive it gets when you get it wrong. There is value in making a weaker prediction because it will cost you less when you get it wrong.
Let’s connect this back to inheritance. Inheritance is a very narrow prediction about the future. It defines strict subtyping relationships. Implicit in the relationship is the assumption that child classes do not overlap, and that they fit in a hierarchical category sharing implementation in a certain way. However, unlike mathematical objects, real-world entities can rarely be categorized hierarchically. The world of web browsers looked hierarchical until they weren’t. File systems were categorized into the "Unix-type" (/ as path separator, and case sensitive), the "Windows-type" (\ as path separator, and case insensitive), until they couldn’t be—HFS+ on MacOS uses / as path separator but it is case-insensitive. Evolution looked like a mathematical tree until we found out about the horizontal gene transfers. Hierarchical categorization is a good aid to understand the world, but it is often not the right tool to describe the truth. Inheritance is a narrow bet that is unlikely to pay off later.
One important thing to note is that the issues of the hierarchical categorization don’t apply when we use them to model an artificial world like mathematics. Every natural number is an integer. The set of all natural numbers don’t overlap with negative integers. We can be assured of this relationship not changing because we defined them that way. The troubles occur when you conflate prescriptive concepts like integers with real-world descriptive concepts like web browsers.
Difficulty of Advocating for Simpler Design
Advocating simpler designs at work could be challenging. It takes a lot of courage and conviction to say, “I don’t know what the future looks like”. Convincing others of this is a fundamentally asymmetric battle. Fancy designs, however wrong they may be in the future, sounds a lot cooler. On the other hand, enumerating all the ways the design could go wrong is much harder. The irony is that it’s harder because future prediction is hard.
This do something vs. do nothing asymmetry can be found in other fields. In medicine, iatrogenesis refers to the harms caused by medical professionals attempting to heal, rather than not doing anything. For example, the misuse of antibiotics brought us the lethal superbugs. Even though antibiotics don’t help with the common cold, many people still believe that it’s effective and demand their doctors give them the drugs. It’s much harder to explain to patients why antibiotics don’t work for colds than to write them a prescription and keep the patients happy. Never mind those micro bacterial superbugs kill thousands every year, unlike the common cold.
It’s human nature to do something than nothing even when it’s harmful to do things. Taleb talks about this problem in his book Antifragile.
What can we do about it
Here’s a very practical set of ideas for all of us to fight this problem.
As an individual developer, you can start building your modules using composition and show your co-workers that there are different, better ways to organize code. The maintenance benefit may not show immediately. One thing that will show immediately, though, is the ease of unit testing, as it is significantly easier to test delegation than different branches of inheritance hierarchy.
If you are using Python and are using the unittest module to write tests, consider switching to pytest. pytest supports the legacy unittest style tests as well so you can have an easy transition.
If you are using C++, you can make use of private inheritance over public when the subtyping relationship is not warranted.
As for Java, I think developers should consider using super-short single-letter member names for trivial compositions that would have been inheritances (e.g., a instead of abstractCollection). Some code reviewers may flinch when they see a single letter variable name, but I don’t think such a reaction is warranted. It’s still clearer than the inherited methods where method names are imported completely unqualified, and possibly from multiple ancestors. Such composition is supported by the same principle that recommends against import *, that it’s bad to import unspecified symbols into the scope. On the other hand, making variable names verbose when its meaning is unambiguous is not supported by any reason.
Finally, you can spread the word by sending your coworkers a link to this blog post.
Why I did not blog for two years
It's 2020 and I realized I haven't written a blog entry for a full two years since the end of 2017. It's not like I don't want to write. On the contrary, I do want to write, which is why I started the blog. I think it is cool to write and I have good ideas that some people and I will find interesting. So I figured I should break the silence this year by why I should write more often by writing about why I didn't write and what I am going to do about it.
The first reason I didn't write is that I feared that my writing will be judged by others. I would think about an interesting topic, lay out the essay in my head, then proceed to criticize it. Thinking too much about WWHNRS-What Would HackerNews Readers Say. Of course, by not writing anything at all, I don't get to find out what people would have said and worst of all, remain unhappy since I wanted to write and get better at it. I realized I have the same pattern with music. I like music and the thought of making new music but as soon as I try making something, I think to my self, this is cheesy, not good enough and so on.
Second, rather than writing something and edit it after, I try to perfect the sentence I am writing. This really hurt me at work last year because I had to write a lot (Amazon is famous for its writing culture). The primary reason for me to write at work was to convey my ideas in an understandable way. Impressing others was perhaps the least important thing to do in that context. Instead, I found myself stuck writing a single paragraph for an hour. It was tiring and was definitely not fun. Most importantly, it did not help me achieve my goal: conveying my ideas to others. In the end, I had to spend extra time trying to rush the rest of the document.
Here's a strange analogy: writing is like vacuuming my home. Hard to get started, but once I start the process, it's fun and it feels good when it's done.
What am I going to do about it? I'll write more this year, at least once every month. Well, that's a bit tautological. More specifically, I will write smaller posts like this one. Many of my past posts have been incredibly long, which are hard to write and even harder to read. I'll be more charitable to myself. It's okay to write something possibly wrong, or just completely wrong, it's not the end of the world. After all, it's not like what's in my head is always right or consistent for that matter.
Stay tuned.
Raspberry Pi thermostat - Python Controller
This is a continuation of the Raspberry Pi thermostat series. The hardware part can be found here.
Summary
With the hardware built, now we need software to control the thermostat.
I decided to use Python for its simplicity. At first, I put up a simple website where I can control the thermostat using my phone. Soon, I realized it's actually easy to integrate with Apple Home via Homebridge so I implemented the interfaces required to get that working as well. Doing that let me do things like "hey siri, set the thermostat to 26 degrees".
The following is the overview of the solution:
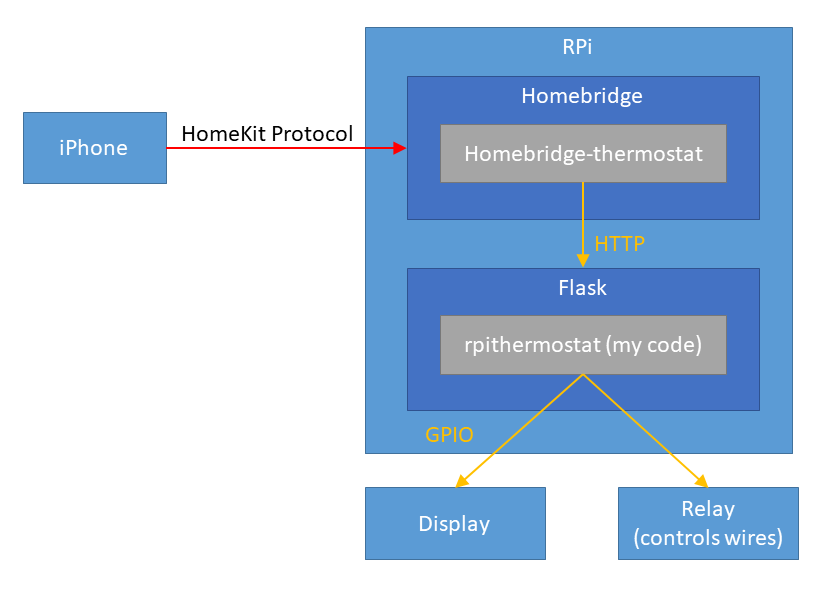
The code is here, but it has lots of features that are not necessarily used today.
Python Server
Libraries
- RPi.GPIO for controlling GPIO pins. This comes with the Raspbian OS already.
- Flask to put up a simple HTTP interface for homebridge.
- DHT11 for interfacing with DHT11 sensor.
- Adafruit_Python_CharLCD to control the 1602 display.
Components
The server just spins up a bunch of servers (implemented as threads) that polls sensors and carry out actions. Whether Python performs well with multi-threading is irrelevant here since the CPU is mostly idle.
There are 5 parts: pconfig, display, temphumids, oracle, and server.
pconfig - for persistent configuration
Since Raspberry Pi can lose power or need to restart for updates, you need to save the configuration on the main disk.
The code is dead-simplee. It just reads from and writes to a JSON file every time you ask. Because the call volume is so low, there is no performance impact to worry about.
Stuff that is saved: * Target temperature day & night - I find that I always want the temperature to be 2 degrees C higher than during the day, so I have a separate profile for that. * Target humidity * Current Governor (see below)
temphumids - temperature & humidity sensor
temphumids records the temperature & humidity every second.
You can also query for the latest sampled temperature & humidity. In reality, I take an average of all the samples collected in the last 30 seconds because DHT11 measurements fluctuate a bit.
display - displays two lines
Display literally accepts two lines to display and just forwards it to the LCD.
oracle - tells controller what to do based on your preference
What the oracle does
is simply to run what I call a 'governor' periodically (30s)
carry out actions. Definitely not the best design but the program is small
enough that it does not really matter much.
I have three governors: off, cool and heat.
| Governor | What they do |
|---|---|
| off | This governor just leaves everything off. |
| cool |
This governor makes sure that your home is cool and dry. The interesting thing
I learned is that leaving the fan ON makes your home very humid even with the
cooling coil on. Apparently the reason is that if the fan is on, the water has
no chance to condense on the coil.
|
| heat | This is pretty simple, it just turns heat on whenever it's cold. It doesn't really care about humidity because there is nothing you can do in winter to improve the situation. |
server - interface for homebridge-thermostat
Homebridge is an open-source NodeJS server that interfaces with Apple Home via HomeKit API.
Using the homebridge plugin homebridge-thermostat, you can just provide the HTTP interface for the thermostat and let your iOS devices control your thermostat. The plugin is poorly documented but I was able to read the source code to find out what APIs you need to implement.
Interfaces you have to implement: * /status return the governor, temperature and humidity information * /targetTemperature/t - set the target temperature * /targetRelativeHumidity/rh - set the target humidity * /off - set governor to off * /comfort - set govenor to heat * /no-frost - set governor to cool
Make the server run on boot
Of course, we want this service to be running all the time. The best way to achieve this is to make it into a systemd service. Making a simple systemd service is very easy. First, write a service definition file like this:
[Unit]
Description=Raspberry Pi Theromostat
After=syslog.target
[Service]
Type=simple
User=pi
Group=pi
WorkingDirectory=/home/pi/src/rpi-repo
ExecStart=/bin/bash -c "FLASK_APP=rpithermostat.server ./venv/bin/flask run --with-threads -h 0.0.0.0"
StandardOutput=syslog
StandardError=syslog
[Install]
WantedBy=multi-user.target
This works great because all the standard out and error just gets redirected to syslog, which is what you want normally anyway.
To install this, just copy the file into /etc/systemd/system/. Then run systemd enable servicename
to make it run when booted up. Run systemd start servicename to start the service right away.
Other caveats
The homebridge would randomly stop working. I never bothered to figure out why, but I "solved"
the issue by just creating a cron job that restarts every hour (0 * * * * systemctl reboot).
It has been working well for many months now without any issues.
Future Improvements
I could improve the heat governor by making it control the power outlet attached to a humidifer in winter. That way I can make the humidity just right.
Raspberry Pi thermostat - Building the hardware
This blog is about building my own thermostat with Raspberry Pi. This is part 1 where I explain the hardware. Part 2 talks about how I build the software that controls it.
What did I not like about the mercury thermostat?
I didn't like my old mercury-based thermostat for a couple reasons. First, the temperature fluctuation was pretty significant, up to 3 degrees C because mercury takes a while to react to the temperature change, Also I didn't like having to go to the living room to adjust the thermostat all the time.
Why did I not just use Ecobee or Nest? This was for fun & to learn how to build basic electronics using RPi ;)
Prerequisite
The interface to the HVAC is a simple single stage 4-wire control.
heatresistive heat strips - white - not used- fan - green
coolingheat pump - orange- power - red
Thank you /u/Nephilimi for the correction.
Basically, you just need to connect the power wire to what you want to turn on.
Connecting power to
heat or
cooling will heat/cool your coil.
Since I live in an apartment equipped with a heat pump, connecting power to heat pump will cool in summer and heat in winter.
Then you also need to run the fan for the air to circulate.
Parts needed
- Raspberry Pi - it can be any model really, but you want wifi for remote control.
- You need 3v, 5v, GND, and 4 GPIO pins minimum. 7 more for a 1602 display.
- Soldering equipments (example)
- Lots (10~20) of female to male jumper cables (example)
- Wires - I just used a 22 gauge wire
- Prototyping board (example)
- 3 x 2.2k and 3 x 10k Resistors
- 3 x 2n2222 NPN transistors
- DHT11 digital temperature & humidity sensor
- Minimum 3 channel relay (this is what I used)
- A 1602 display, if you want to display status also. It's named 1602 because it displays 2 rows of 16 characters.
Circuit
Here's the schematic for the core parts:
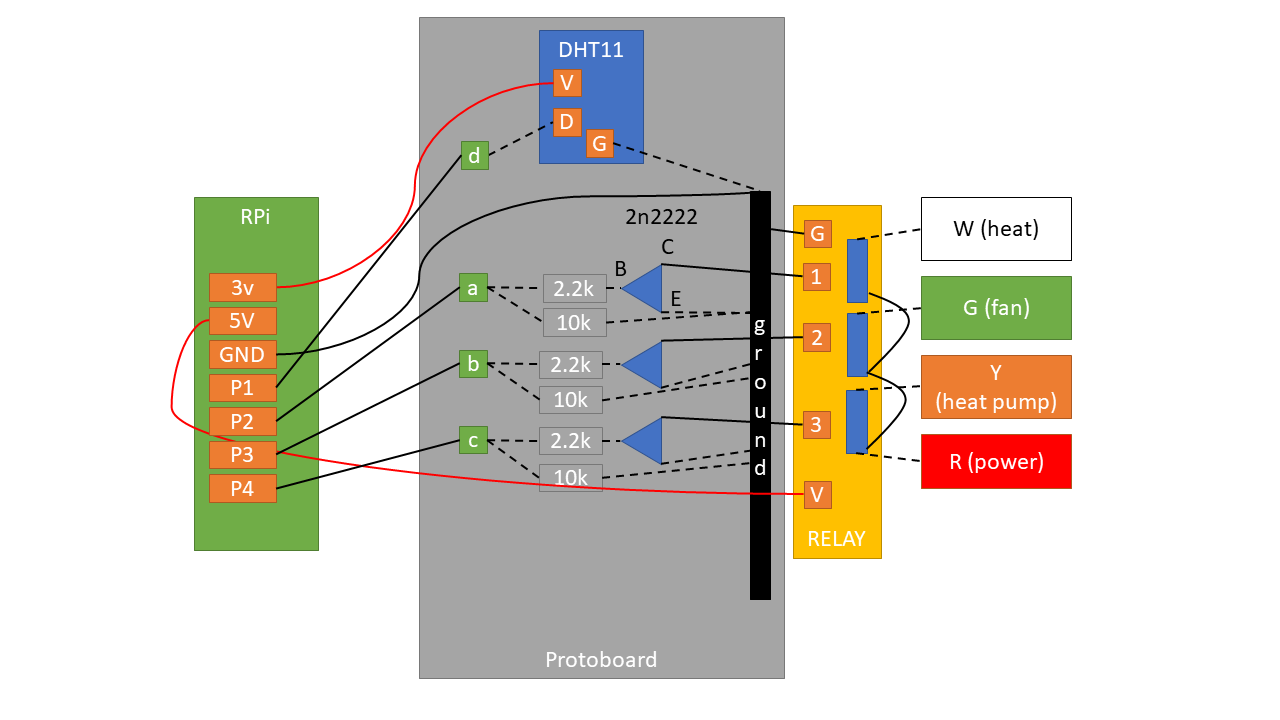
Solid lines denote where I had to use a wire. Dotted lines denote where I didn't have to use a separate wire thanks to either the board or existing wires.
Pins
P1 ~ P4 denote any free GPIO pins.
- 3.3v to power DHT11.
- 5v to power the relay.
P1communicates with DHT11 (both read/write).P2~P4controls the three relay outputs.
Communicating with DHT11
DHT11 needs only one data pin because it both handles input and output through the same pin.
Controlling the relay
This was the only non-straightforward part that required a bit of thinking. When the relay is powered, the switches are simply disconnected. In order to 'close' (or, connect) the switch, you need to drain the current from the relay pins.
This is where the NPN transistor helps. It has 3 parts: base (B), current (C) and
emitter (E). Electricity flows from C to E, only if voltage is
applied on B.
In this case, C accepts current from the relay, but it doesn't let it go through
E unless B has voltage. And we control the voltage by setting the line high
from the Rpi.
So in my circuit, asserting P1 high connects power to
heat. P2 and P3
controls fan and cooling
respectively.
Finished hardware
Here's a ghetto looking finished thermostat in action:

Due to my lack of any real hardware skills, I could not put together in a more polished way.
What's next?
Check out the part 2 for the software that runs this thermostat.